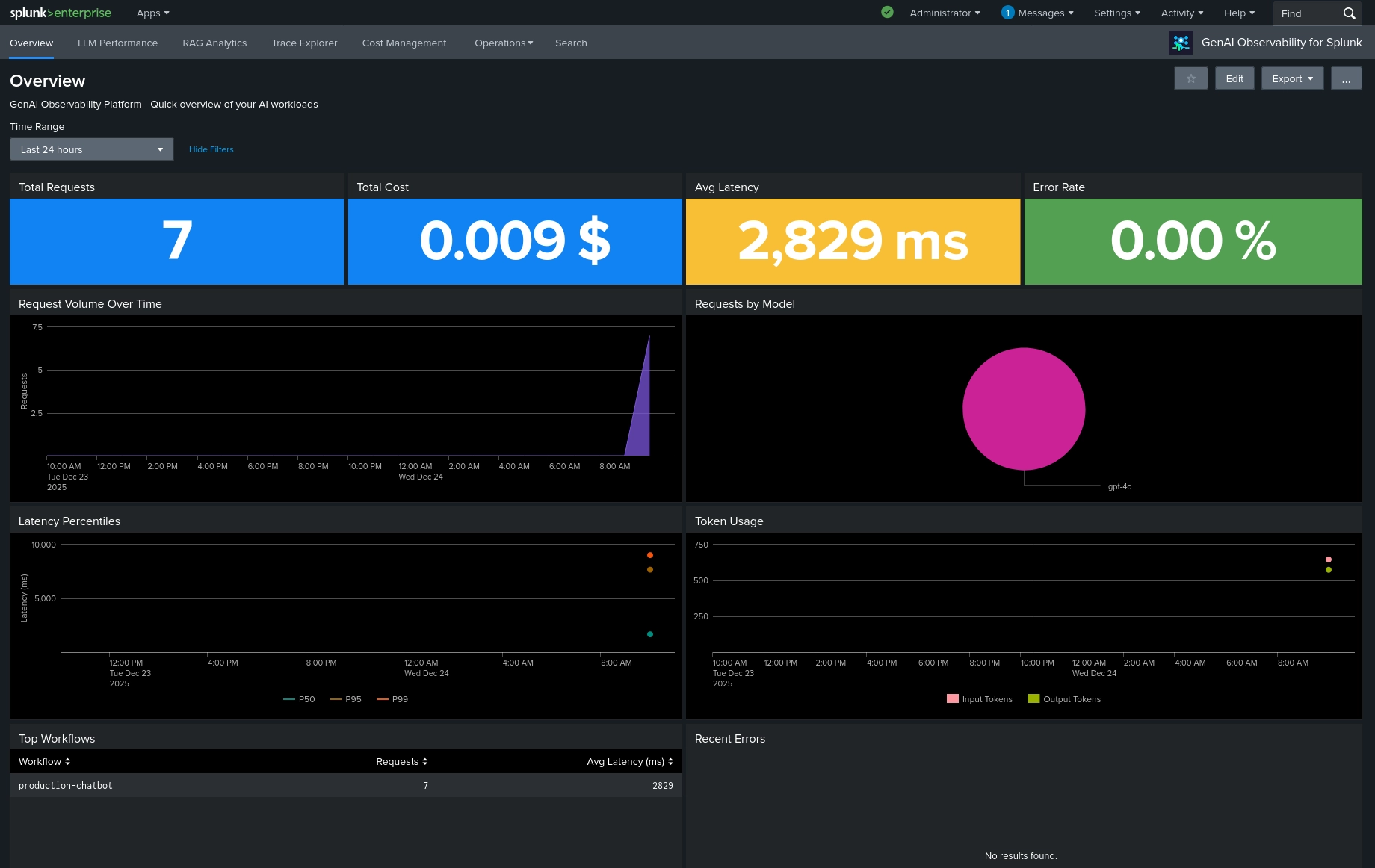
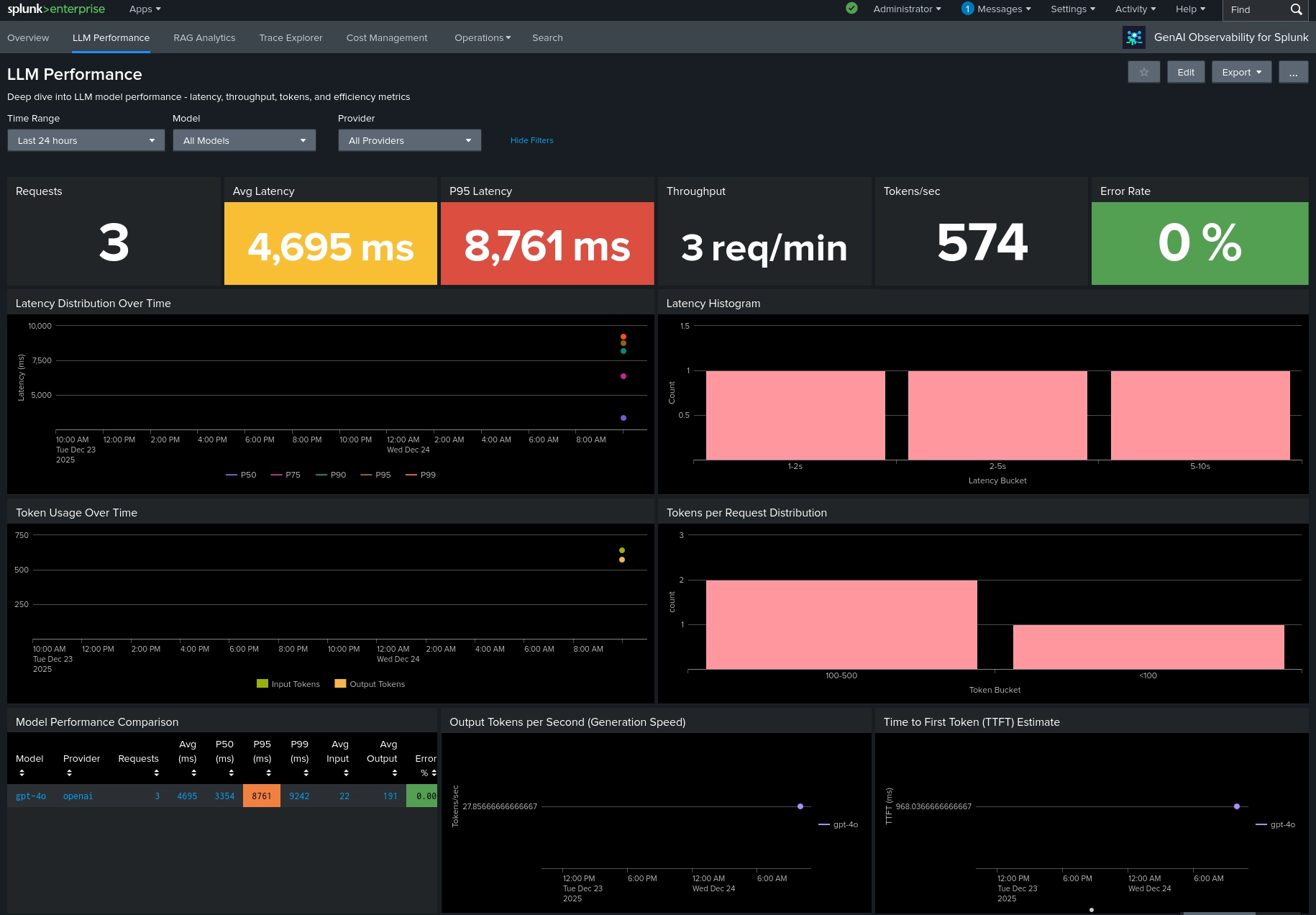
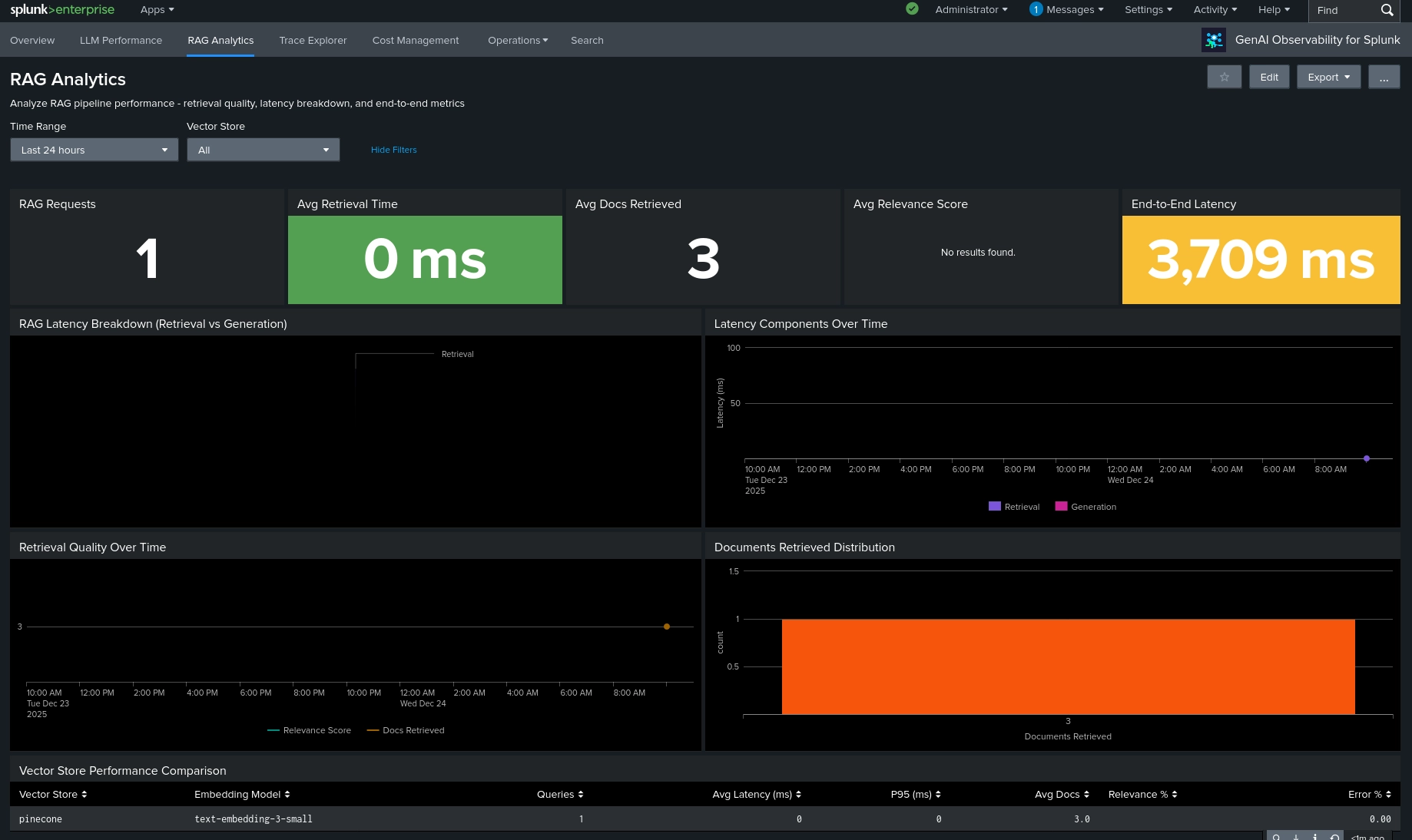
GenAI Observability for Splunk provides production monitoring for LLM, RAG, and
agent applications — track token usage, latency, cost, retrieval quality, and
errors across OpenAI, Anthropic, LangChain, and more.
**Works with any OpenTelemetry GenAI pipeline — no custom SDK required.**
If you already emit OpenTelemetry GenAI traces (gen_ai.* semantic conventions),
point your OpenTelemetry Collector at Splunk and the dashboards light up — with
no changes to your application code. Prefer a turnkey setup? An optional
lightweight Python SDK instruments your code with simple decorators.
Key Features:
- Ingests standard OpenTelemetry GenAI traces (gen_ai.* semantic conventions) via the OpenTelemetry Collector
- Real-time monitoring of LLM calls, RAG pipelines, and AI agents
- Token usage tracking with cost estimation (bundled model-pricing lookup)
- Latency analysis with P50, P95, P99 percentiles and tokens/sec
- Error detection and alerting
- Pre-built dashboards for immediate insights
- Optional Python SDK for one-line, decorator-based instrumentation
- Works with OpenAI, Anthropic, LangChain, LlamaIndex, and any OpenTelemetry-instrumented framework
- Data model acceleration to speed up reporting and dashboard performance on extremely large datasets
Use Cases:
- Monitor production AI applications
- Optimize token usage and reduce costs
- Debug slow or failing LLM calls
- Track AI spend by model, workflow, or user
- Ensure SLA compliance for AI services
Bring your existing OpenTelemetry pipeline, or use the optional SDK — either way
you get ready-to-use dashboards, model-pricing lookups, and a collector recipe
to get started in minutes.
Docs, examples, and the collector configuration: https://github.com/rootiq-ai/splunk_genai_observability/