Default Version 5.2.4
May 22, 2026
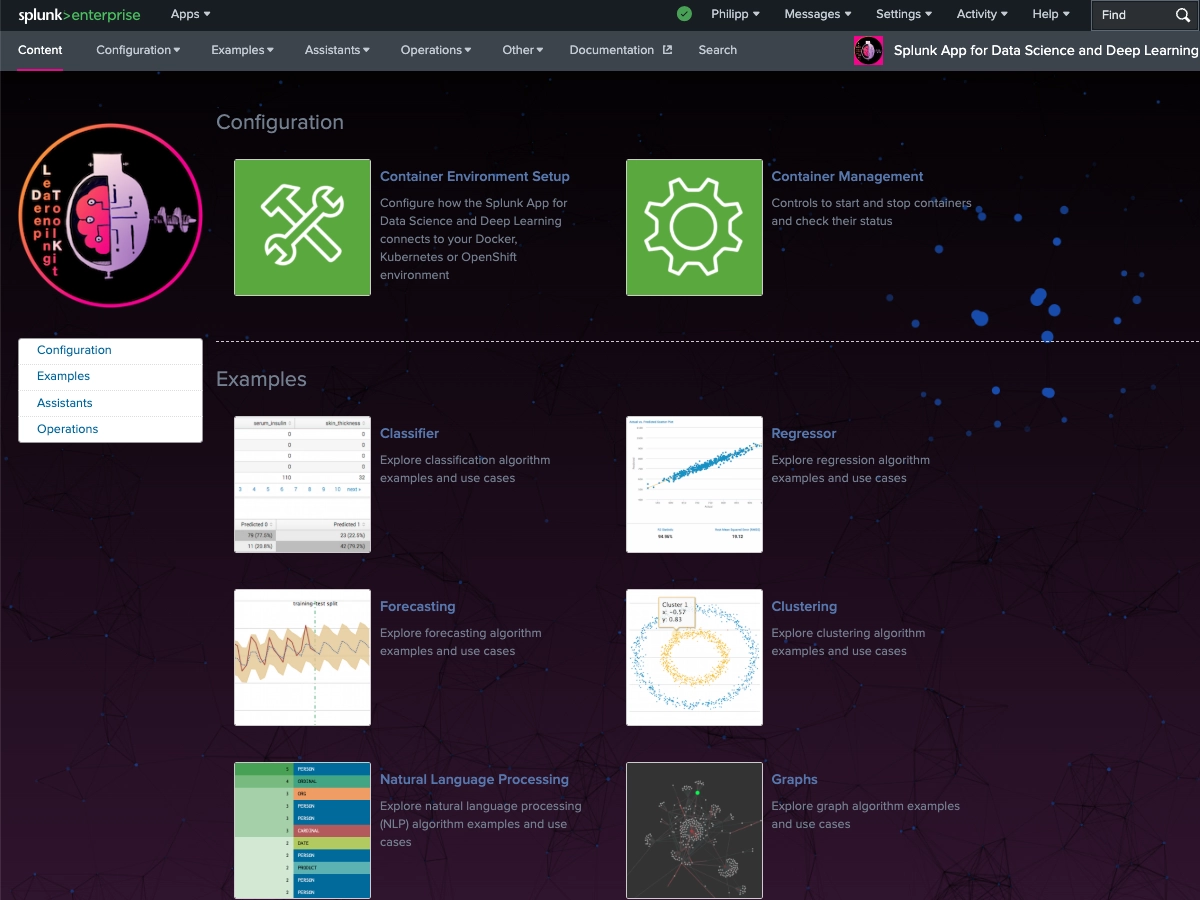
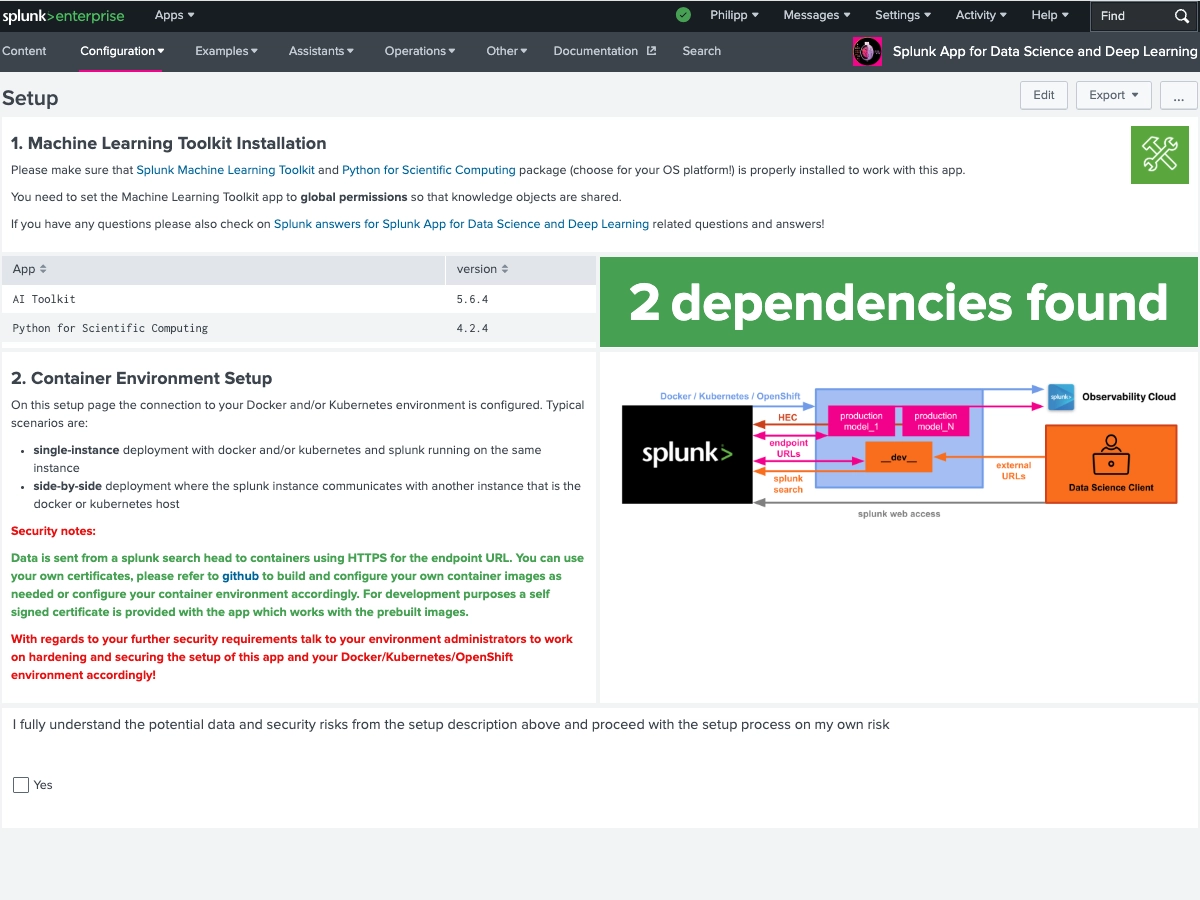
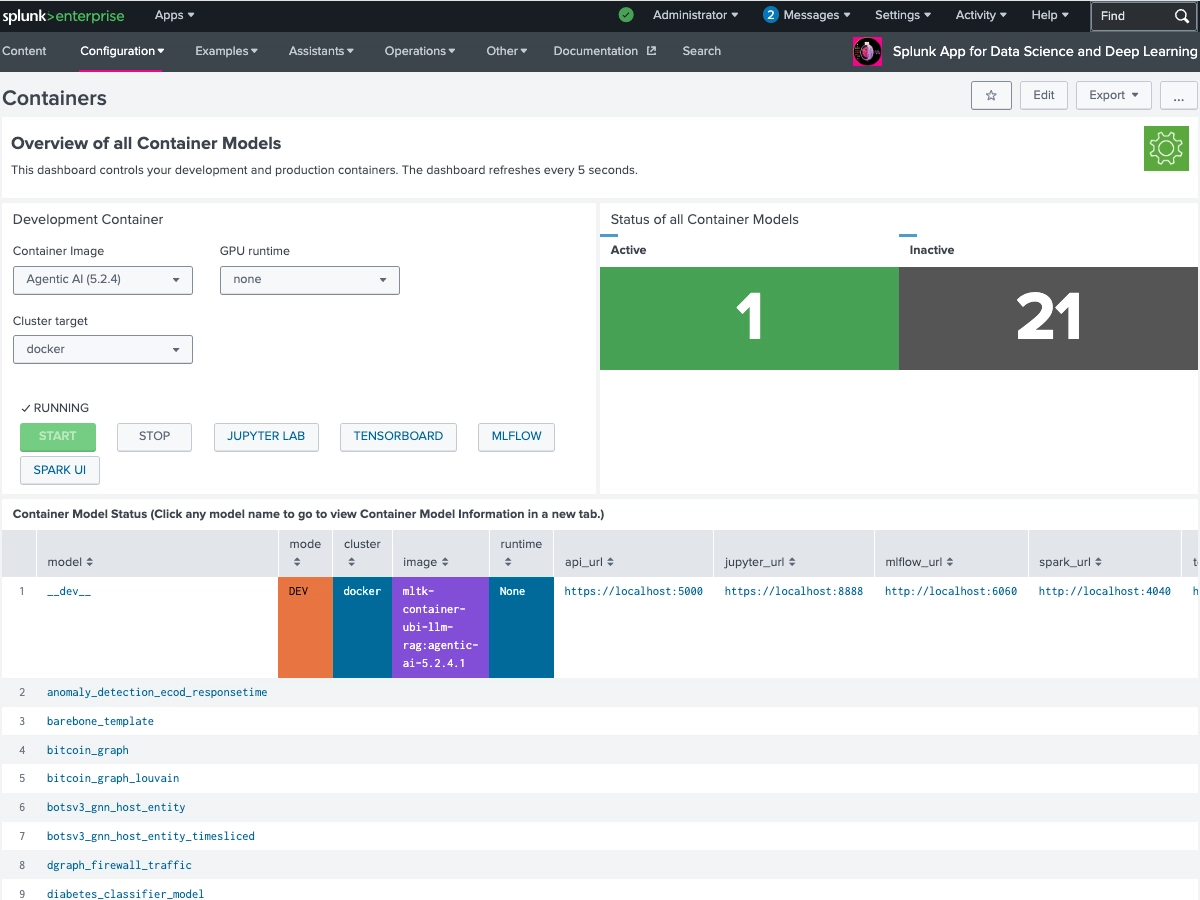
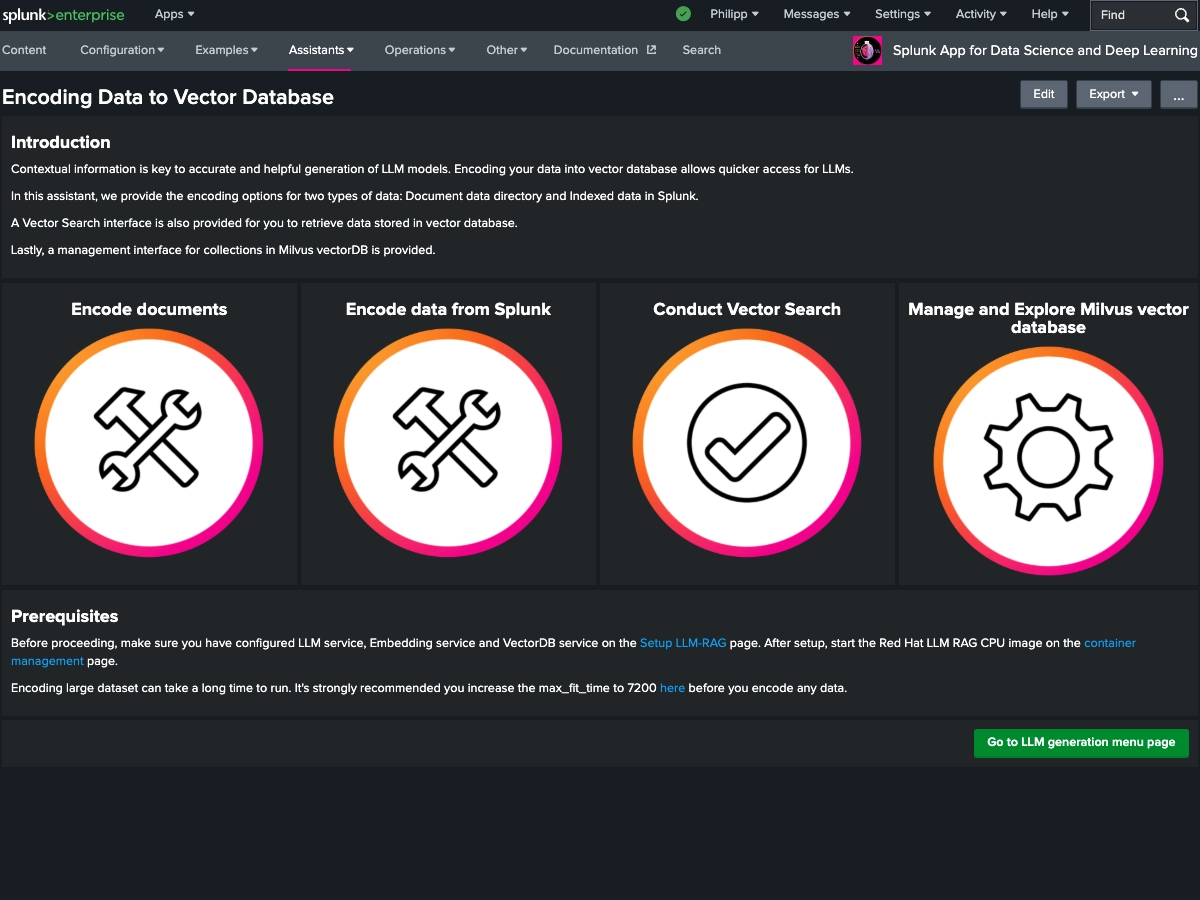
The Splunk App for Data Science and Deep Learning (DSDL), formerly known as the Deep Learning Toolkit (DLTK), lets you integrate advanced custom machine learning and deep learning systems with the Splunk platform. DSDL extends the Splunk AI Toolkit (AITK), formerly known as the Machine Learning Toolkit (MLTK), with prebuilt Docker containers for TensorFlow, PyTorch, and a collection of data science, NLP, machine learning and advanced AI libraries. By using predefined workflows for rapid development with Jupyter Lab Notebooks, DSDL enables you to build, test, and operationalize your custom AI models with Splunk. You can leverage GPUs for compute intense training tasks or LLM inference and flexibly deploy models on CPU or GPU enabled containers. The app ships with 40+ examples that showcase different artificial intelligence, deep learning and machine learning algorithms for classification, regression, forecasting, clustering, graph analytics, and natural language processing tasks. Learn from these examples to tackle your most advanced data science and custom AI use cases in the areas of IT Operations, Security, Application Development, IoT, Business Analytics, and beyond.
(8)
Categories
Created By
Contributors
Source Code
DSDL Github(Opens new window)Type
Downloads
Featured in Collection
Splunk Answers
Ask a question about this app listing(Opens new window)Resources