Last Updated
May 27, 2023
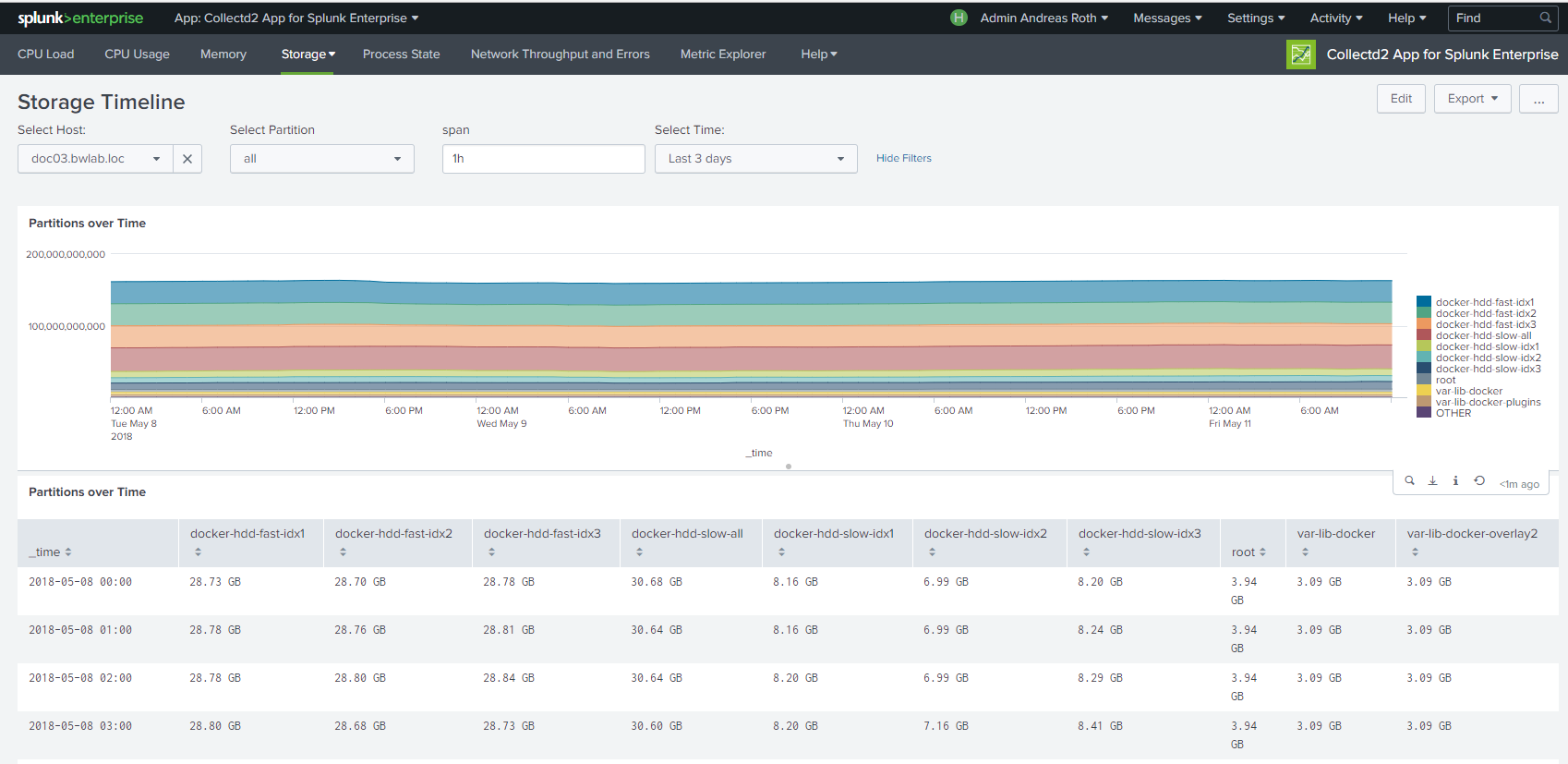
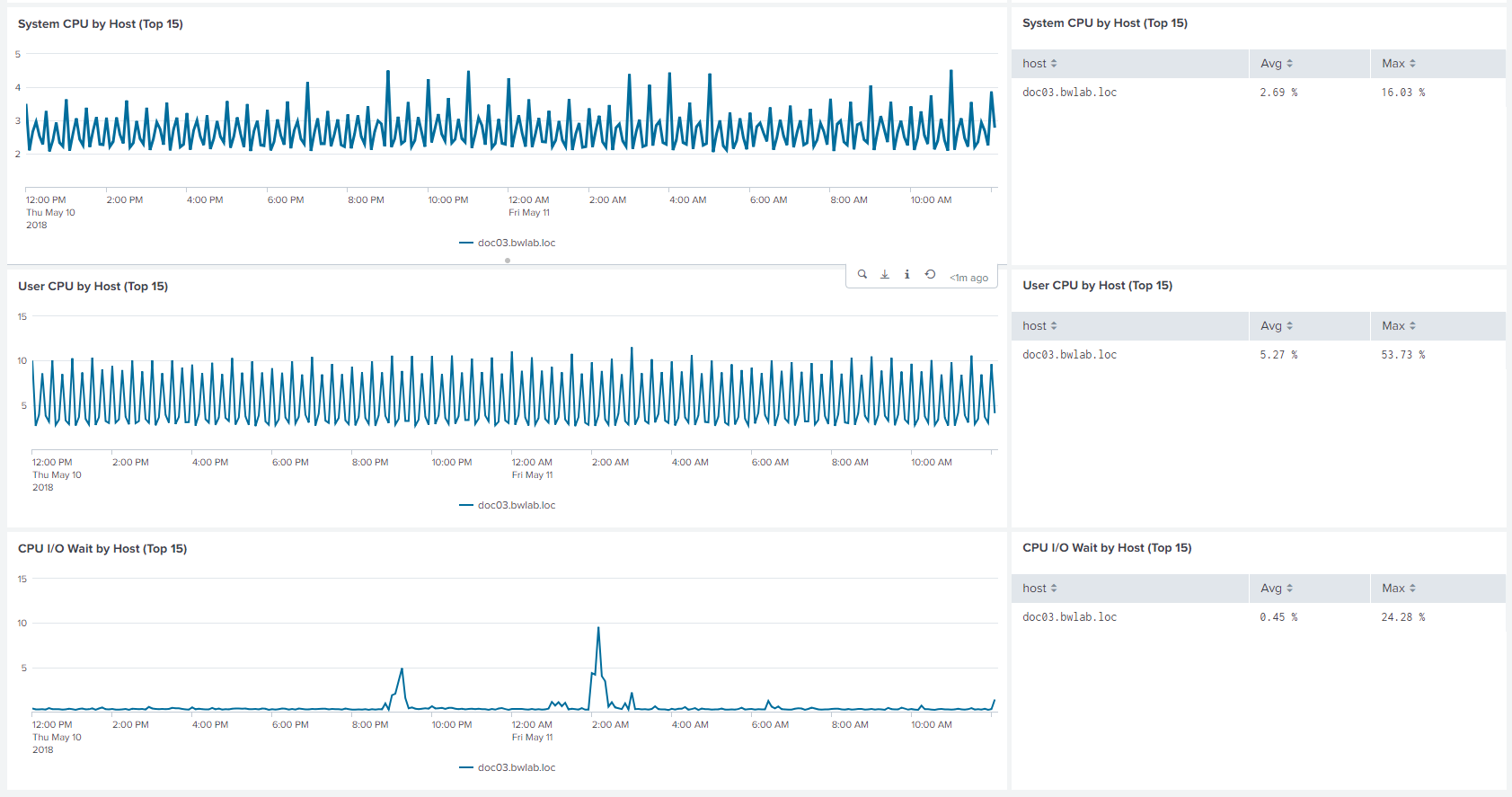
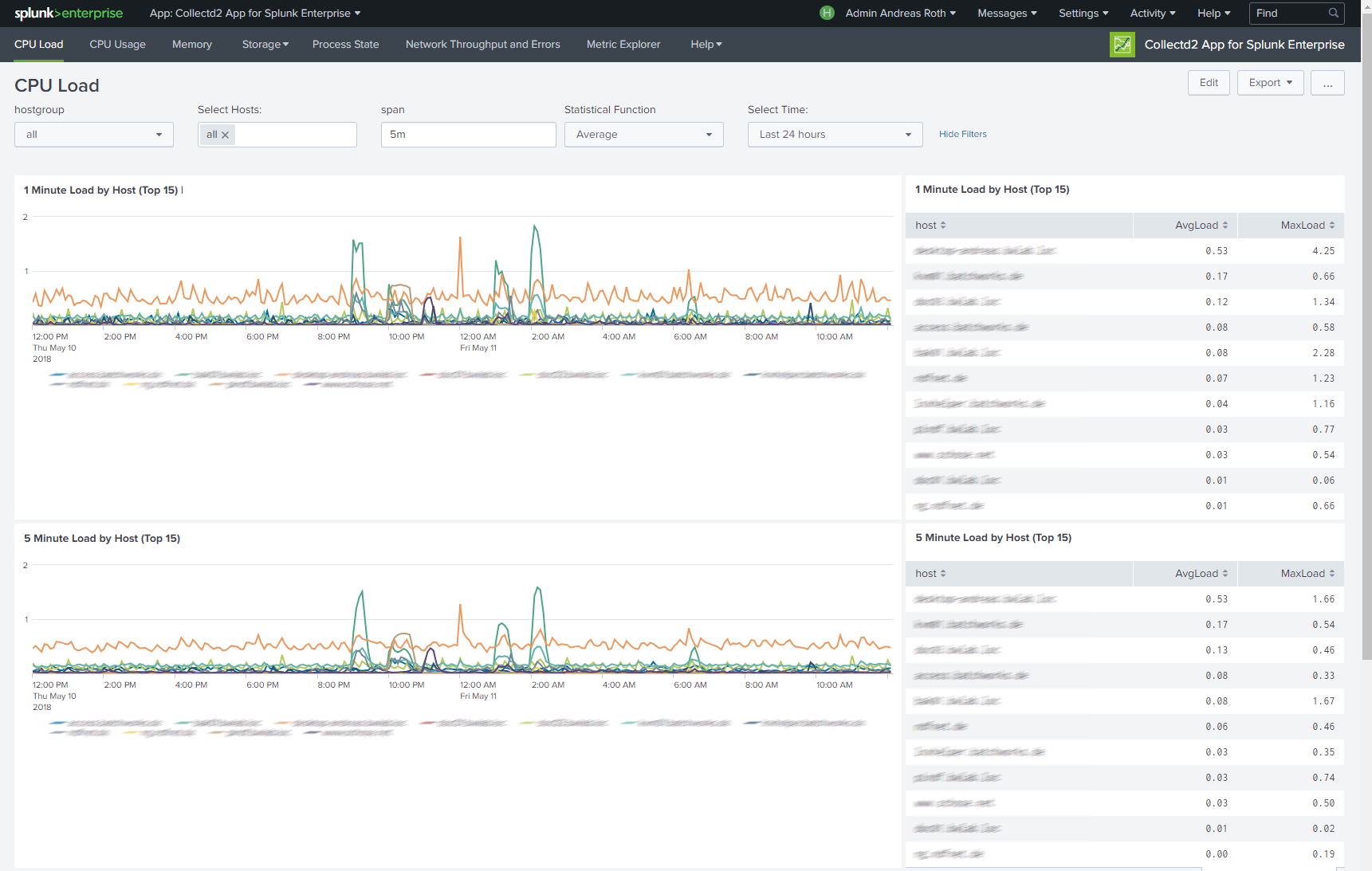
The "collectd2 App for Splunk Enterprise" analyzes your collectd metrics. Those statistics can then be used to find current performance bottlenecks and predict future system load. It uses the collectd daemon and http plugin on the client side and the Splunk HTTP Event Collector on the server side to gather data from client machines.
(0)
Categories
Created By
Type
Downloads
Splunk Answers
Ask a question about this app listing(Opens new window)Resources