Latest Version 2.1
September 25, 2016
This app is archived. App archiving documentation
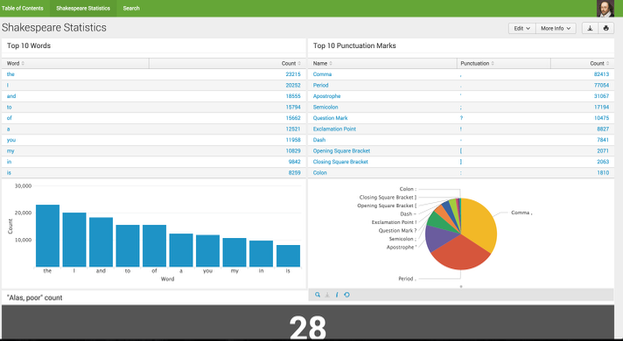
While I was having a few pints with my colleagues they said:
(0)
Categories
Created By
Type
Downloads
Splunk Answers
Ask a question about this app listing(Opens new window)Resources