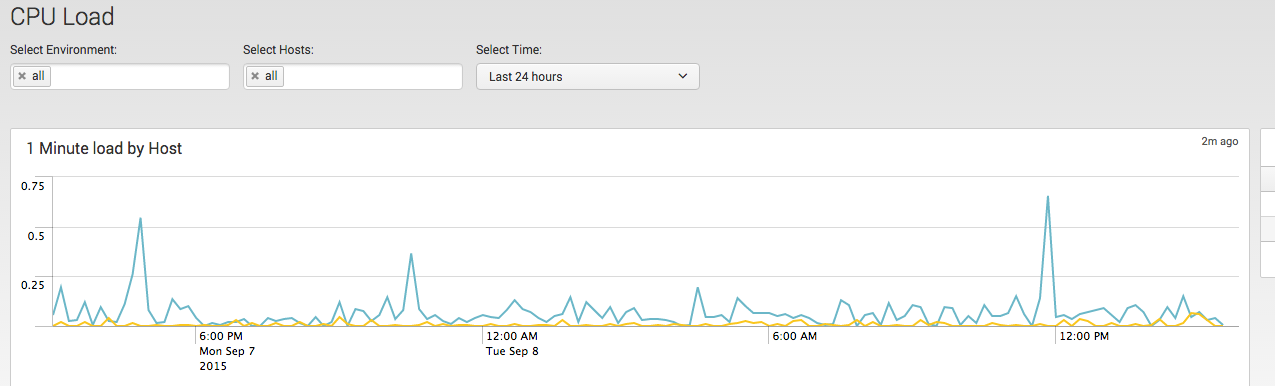
Overview
The "Collectd App for Splunk Enterprise" analyses your OS performance and storage data. Those statistics can then be used to find current performance bottlenecks and predict future system load. It uses the collectd daemon and the graphite plugin to gather data from client machines.
Features:
Analyze System Load
Analyze CPU Usage (overall and per core)
Memory Usage (used, cached, buffered, swapped, free memory)
Storage Trending (in-/decrease per host and per partition)
Storage Timeline (Host and Partition usage over time)
Storage Performance (IOPs, Latency, Volume) by Host and Partition
Process State (running, sleeping, blocked and zombie processes) over time
Network Throughput and Errors (Packets/s) by Host and Interface