The Charge Back App is intended to calculate maintenance and yearly run rates for Splunk.
Please note: this app is no longer supported, use the NEW Chargeback App for Splunk Cloud https://splunkbase.splunk.com/app/5688/ instead.
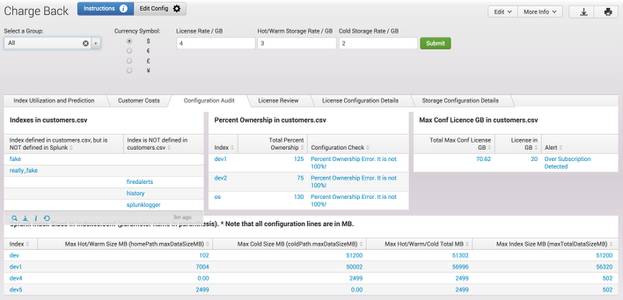
If you are running Splunk in a medium to large environment, you are probably sharing Splunk with other groups. In many places, this results in one group running Splunk as a service for any number of internal customers. The challenge then becomes sharing the maintenance and run costs of the infrastructure. As a Splunk administrator, I would have to run several long-running searches to try and figure out the costs. This App should put all of that to rest.